
| HOME | ABOUT | PEOPLE | PROJECTS | PUBLICATIONS | LINKS | (WIKI) |
|
Human Action Recognition by Semi-Latent Topic Models
Introduction
We propose two new models for human action recognition from video sequences using topic models. Video sequences are represented by a novel ``bag-of-words'' representation, where each frame corresponds to a ``word''. Our models differ from previous latent topic models for visual recognition in two major aspects: first of all, the latent topics in our models directly correspond to class labels; secondly, some of the latent variables in previous topic models become observed in our case. Our models have several advantages over other latent topic models used in visual recognition. First of all, the training is much easier due to the decoupling of the model parameters. Secondly, it alleviates the issue of how to choose the appropriate number of latent topics. Thirdly, it achieves much better performance by utilizing the information provided by the class labels in the training set. We present action classification results on five different datasets. Our results are either comparable to, or significantly better than previous published results on these datasets.
Method Overview
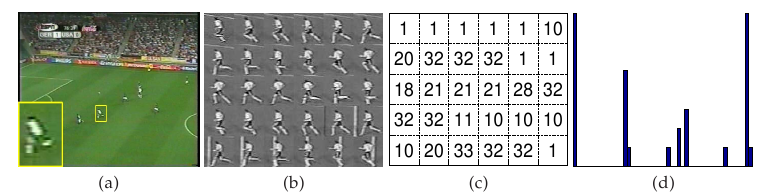
The following figure shows the processing pipeline of our method: (a) given a video sequence, (b) track and stabilize each human figure, (c) represent each frame by a ``motion word'', (d) ignore the ordering of words and represent the image sequences of a tracked person as a histogram over ``motion words''.
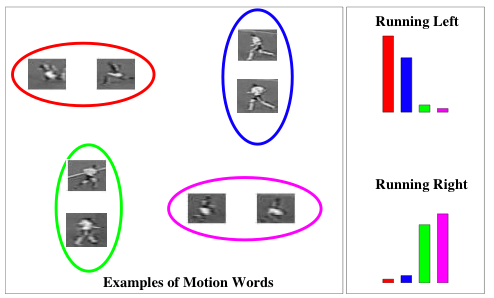
Our work can be seen as a new way of capturing ``temporal structure'' of a video. we capture ``temporal smoothing'' via co-occurrence statistics amongst these visual words, i.e., which actions tend to appear together in a single track. For example, in a single track of a person, the combination of ``walk left'' and ``walk right'' actions is much more common than the combination of ``run left''``run right''``run up''``run down''. There has been previous work that tries to model the full dynamics of videos using sophisticated probabilistic models~(e.g., hidden Markov models, dynamic Bayesian networks). But the problem with this approach is that those sophisticated models impose too many assumptions and constraints~(e.g., the independence assumption of hidden Markov models) in order to be tractable. It is also hard to learn those models since there are usually a large number of parameters that need to be set. Instead, our methods can be considered as a way of imposing a ``rough'' constraint on the overall temporal structures of videos, without worrying about the detailed temporal information between adjacent frames. Dataset
The ballet dataset used in this paper can be downloaded here. It is from a ballet instruction DVD.
Other datasets used: KTH dataset, Weizmann dataset, soccer dataset, hockey dataset. Publications
|
|
Vision and Media Lab, Simon Fraser University
TASC 8000 and 8002, 8888 University Drive, Burnaby, BC, V5A 1S6, Canada |