About the SFU Vision and Media Lab
The SFU Vision and Media Laboratory conducts research in
Computer Vision and Multimedia. We focus on the problems of active video, content-based retrieval,
human activity recognition, lighting invariance, object recognition,
and shape matching.
High-level descriptions of each of these problems appear
below. Please see our list of projects for details on the research
conducted by the Vision and Media Laboratory.
Human Activity Recognition
|
The grand goal of the field of human activity recognition is to build
systems that can find human figures in either still images or video
sequences, and determine what action they are performing. Such
systems can be applied to develop more natural interfaces to
computers, for example using gestures, in addition to being used for
surveillance and security.
|
 |
Lighting Invariance
|
One of the pieces of the puzzle is how to deal with lighting change in
the way that humans can: we tend to ignore the effects of shading and
shadows, and we use bright highlights as a useful visual cue, rather
than a source of confusion. But computer programs aiming at image
understanding see these factors as distractions. So one strand of
research in the VML looks at removing these distracting factors using
image processing to produce images that are invariant to lighting
change. One compelling outcome of this work has been the development
of images that are unchanged from the original, except that the
shadows are removed.
|
 |
Object Recognition
|
Object recognition refers to the problem of automatically identifying
objects in images. These objects can range from household items such
as mugs, tables, or telephones, to discriminating between various
species of fish. The approaches we are developing use the overall
shape of an object to aid in making these distinctions.
|
 |
Active Video
|
Active videos are object-centered, and often exhibit prominent
shifting and holding behaviors of the human operator. In order to
capture the object-of-interest and its movements, it is common for the
videographer to invoke various camera movements. The rapid pan/tilt
movement is analogous to saccades, which are often triggered by object
movements or distinct visual features (color, texture, shape, etc.) in
the periphery, indicating a shift of attention. When dealing with
moving objects, smooth (and usually not so rapid) pan/tilt movements
are used for smooth pursuit. When multiviews of the object are
desirable, we will witness body movement of the videographer. In
short, active video is by definition object-based and full of actions.
This research focuses on the automatic extraction of video objects
from active video and their 3D reconstruction, which will facilitate
video indexing and retrieval.
|
 |
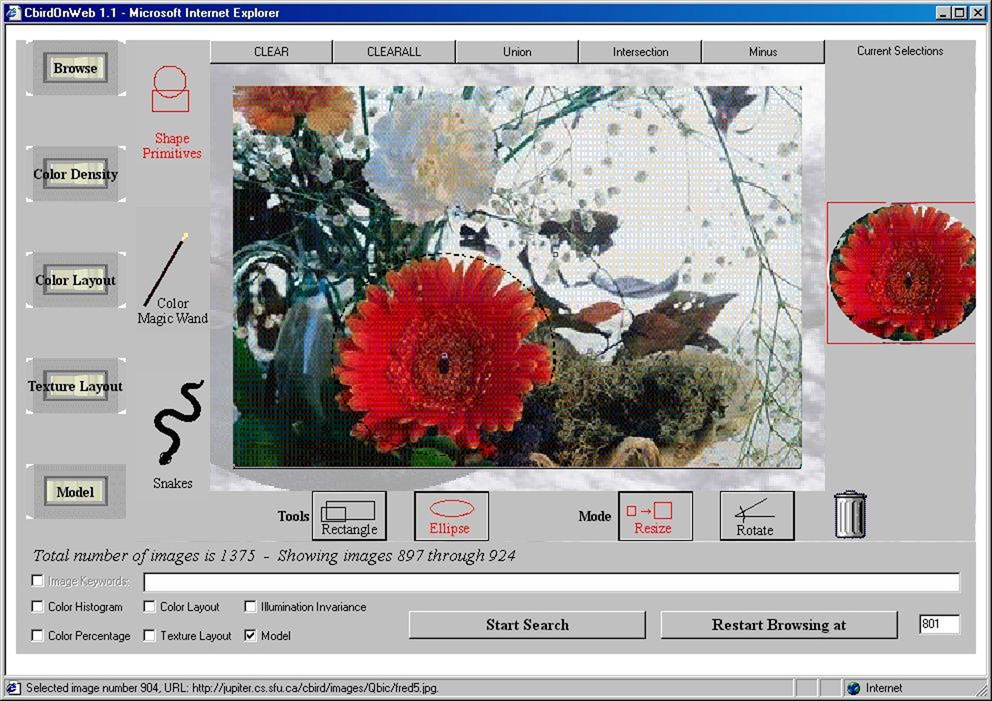
Content-based Image Retrieval
|
C-BIRD allows users to retrieve image and video contents from the
internet. In addition to keywords, it uses common features
such as color, texture, shape and their conjuncts. This research
focuses on issues of Search by Illumination Invariance and Search by
Object Model.
|
 |
Directions to the SFU Vision and Media Lab
Simon Fraser University is situated on Burnaby
Mountain in Greater Vancouver. The SFU Vision and
Media Lab is located in the TASC1 building, rooms 8000
and 8002.
Visitors who are driving to the VML should park in the "Visitor's B-lot"
(VB), accessed from Tower Road.
For public transit information, please see the directions given in the links below.
 How to get to SFU How to get to SFU
 SFU Campus Map SFU Campus Map
 Google map with SFU's location Google map with SFU's location
Google Transit public transit directions to SFU
|
