

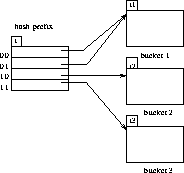
Figure 8.10: General extendable hash structure.
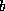 -bit binary integers (typically b=32).
-bit binary integers (typically b=32).
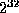 is over 4 billion, so we don't generate that many buckets!
bits
of the hash initially.
is over 4 billion, so we don't generate that many buckets!
bits
of the hash initially.
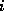 bits where
bits where 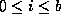 .
bits are used as an offset into a table of bucket addresses.
grows and shrinks with the database.
appearing over the bucket address table tells how
many bits are required to determine the correct bucket.
.
.
bits are used as an offset into a table of bucket addresses.
grows and shrinks with the database.
appearing over the bucket address table tells how
many bits are required to determine the correct bucket.
.
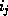 .
.
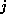 is then
is then 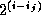 .
.
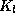 :
:
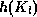 .
high order bits of .
-bit string.
.
.
high order bits of .
-bit string.
.
1. If 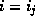 , then only one entry in the bucket address table
points to bucket .
, then only one entry in the bucket address table
points to bucket .
.
by one, thus considering more of the hash, and
doubling the size of the bucket address table.
 , and set the second pointer to point to
.
and
, and set the second pointer to point to
.
and 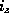 to .
which are put in either or .
again.
to .
which are put in either or .
again.
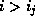 , then more than one entry in the bucket address table
points to bucket .
without increasing the size of the
bucket address table (why?).
correspond to hash
prefixes that have the same value on the leftmost bits.
, and set and to the
original value plus 1.
.
, and make the rest
point to bucket .
as before.
.
, then more than one entry in the bucket address table
points to bucket .
without increasing the size of the
bucket address table (why?).
correspond to hash
prefixes that have the same value on the leftmost bits.
, and set and to the
original value plus 1.
.
, and make the rest
point to bucket .
as before.
.
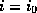 , we need to increase the number of bits we use
from the hash.
, we need to increase the number of bits we use
from the hash.
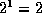 buckets.
buckets.
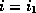 .
.