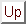Index schemes force us to traverse an index structure.
Hashing avoids this.
Hashing involves computing the address of a data item by computing a
function on the search key value.
A hash function h is a function from the set of all search key values
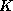 to the set of all bucket addresses
to the set of all bucket addresses 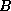 .
.
- We choose a number of buckets to correspond to the number of search key
values we will have stored in the database.
- To perform a lookup on a search key value
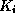 , we compute
, we compute
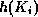 , and search the bucket with that address.
, and search the bucket with that address.
- If two search keys
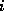 and
and 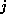 map to the same address, because
map to the same address, because
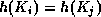 , then the bucket at the address obtained will contain
records with both search key values.
, then the bucket at the address obtained will contain
records with both search key values.
- In this case we will have to check the search key value of every record
in the bucket to get the ones we want.
- A good hash function gives an average-case lookup that is a small
constant, independent of the number of search keys.
- We hope records are distributed uniformly among the buckets.
- The worst hash function maps all keys to the same bucket.
- The best hash function maps all keys to distinct addresses.