An index record appears for every search key value in file.
This record contains search key value and a pointer to the actual record.
Sparse Index:
Index records are created only for some of the records.
To locate a record, we find the index record with the largest search key
value less than or equal to the search key value we are looking for.
We start at that record pointed to by the index record, and proceed
along the pointers in the file (that is, sequentially) until we find the
desired record.
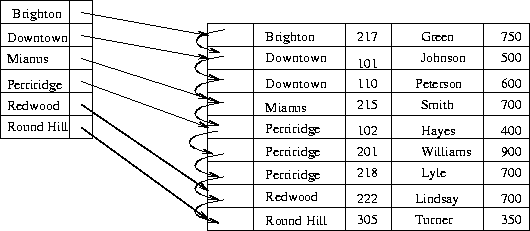
Figures 11.2 and 11.3 show dense and
sparse indices for the deposit file.
Figure 11.2: Dense index.
Notice how we would find records for Perryridge branch using both methods.
(Do it!)
Figure 11.3: Sparse index.
Dense indices are faster in general, but sparse indices require less
space and impose less maintenance for insertions and deletions. (Why?)
A good compromise: to have a sparse index with one entry per block.
Why is this good?
Biggest cost is in bringing a block into main memory.
We are guaranteed to have the correct block with this method, unless
record is on an overflow block (actually could be several blocks).