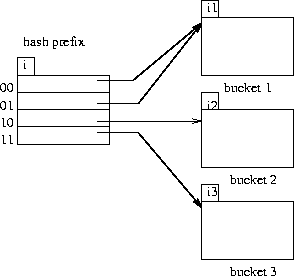
Two cases exist:
1. If 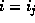 , then only one entry in the bucket address table
points to bucket j.
, then only one entry in the bucket address table
points to bucket j.
- Then we need to increase the size of the bucket address table so that
we can include pointers to the two buckets that result from splitting
bucket j.
- We increment i by one, thus considering more of the hash, and
doubling the size of the bucket address table.
- Each entry is replaced by two entries, each containing original value.
- Now two entries in bucket address table point to bucket j.
- We allocate a new bucket z, and set the second pointer to point to
z.
- Set
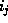 and
and 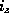 to i.
to i. - Rehash all records in bucket j which are put in either j or z.
- Now insert new record.
- It is remotely possible, but unlikely, that the new hash will still
put all of the records in one bucket.
- If so, split again and increment i again.
2. If 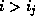 , then more than one entry in the bucket address table
points to bucket j.
, then more than one entry in the bucket address table
points to bucket j.
- Then we can split bucket j without increasing the size of the
bucket address table (why?).
- Note that all entries that point to bucket j correspond to hash
prefixes that have the same value on the leftmost bits.
- We allocate a new bucket z, and set and to the
original value plus 1.
- Now adjust entries in the bucket address table that previously
pointed to bucket j.
- Leave the first half pointing to bucket j, and make the rest
point to bucket z.
- Rehash each record in bucket j as before.
- Reattempt new insert.