To get fast random access to records in a file, an index structure is
used.
Each index structure is associated with a particular search key.
Text does not distinguish clearly between primary, secondary
and clustering indices.
We'll use definitions from Elmasri & Navathe ([ELNA89]).
If the file is sequentially ordered on a primary key, an index
on that key is called the primary index.
An index on non-key attribute(s) the file is sorted on is called
a clustering index.
Indices on attributes the file is not sorted on are called
secondary indices.
Sequentially-ordered files having a primary index are called
index-sequential files.
Figure 8.1 shows a sequential file for deposit
records.
Figure 8.1: Sequential fiel for deposit records.
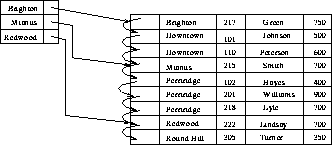
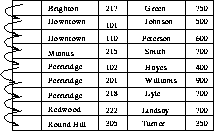
Figures 8.2 and 8.3 show dense and
sparse indices for the deposit file.
Figure 8.2: Dense index.
Notice how we would find records for Perryridge branch using both
methods. (Do it!)
Figure 8.3: Sparse index.
Dense indices faster in general.
Sparse indices require less space.
Sparse indices impose less maintenance for insertions and deletions.
(Why?)
Good compromise ``trade-off'' solution:
Have a sparse index with one index entry per block.
Why is this good?
Biggest cost is in bringing a block into main memory.
We are guaranteed to have the correct block with this method, unless
record is on an overflow block (actually could be several blocks).
Index size still small.
Even with a sparse index, index size may grow too large.
For 100,000 records, 10 per block, at one index record per block,
that's 10,000 index records!
Even if we can fit 100 index records per block, this is 100 blocks.
If index is too large to be kept in main memory, a search results in
several disk reads.
If there are no overflow blocks in the index, we can use binary search.
This will read as many as blocks (as many as 7 for
our 100 blocks).
If index has overflow blocks, then sequential search typically used,
reading all index blocks.
(Note: I think that some variation of binary search could be created
for indices with overflow blocks.
This would be faster than sequential search.)
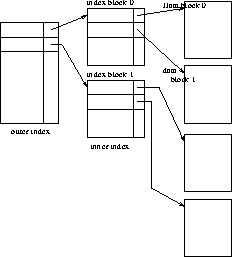
Solution: Construct a sparse index on the index
(Figure 8.4).
Figure 8.4: Two-level sparse index.
Use binary search on outer index.
Scan index block found until correct index record found.
Use index record as before - scan block pointed to for desired record.
For very large files, additional levels of indexing may be required.
Indices must be updated at all levels when insertions or deletions
require it.
Frequently, each level of index corresponds to a unit of physical
storage (e.g. indices at the level of track, cylinder and disk).
Deletion:
Have to find the record
If last record with a particular search key value, delete
that search key value from index.
For dense indices this is like deleting a record in a file.
For sparse indices, delete a key value by replacing key value's entry
in index by next search key value.
If that value already has an index entry, delete the entry.
Insertion:
Find place to insert.
Dense index: insert search key value if not present.


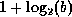 blocks (as many as 7 for
our 100 blocks).
blocks (as many as 7 for
our 100 blocks).
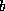 index blocks.
index blocks.