Adversarial Search¶
Note¶
we’re not going to cover the algorithms in this chapter in significant detail
they are mostly specific to turn-taking games like chess and Go
recent developments in reinforcement learning have dramatically altered the state of the start of game playing algorithms
while min/max alpha-beta search is still a good algorithm that powers many strong game-playing programs, other techniques have eclipsed it in games like chess and Go
Min/max Search¶
in games like chess, Go, poker, Connect-4, etc., adversarial search techniques have traditionally been used to create intelligent computer players for these games
assuming a 2-player game like chess, the basic idea is to represent the game as a game tree, where nodes in the tree alternate between one players move and the others
the players are often generically named MIN and MAX, corresponding to how they want to influence the objective function
- MIN wants to minimize the objective function, while MAX wants to maximize it
the MINIMAX algorithm is the basic search techniques that computers use for making moves
the basic idea is to evaluate the leaves of the game tree, and then to work upwards from those using the minimax rule to assign values to the nodes for each player
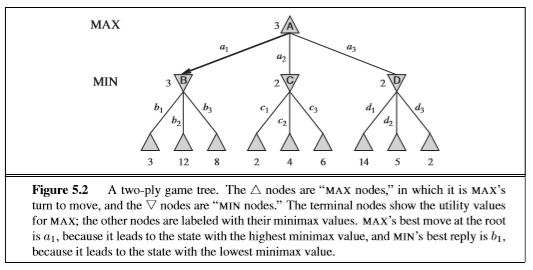
in practice, MINIMAX search is usually implement with alpha-beta pruning, an effective technique for efficiently discarding certain parts of the game tree
dozens of other tricks, techniques, and ideas have been tried and tested over the decades of research into these algorithms, so that today the best adversarial search algorithms are highly optimized and efficient
here are some other tricks used in games like chess:
opening books: a database of thousands (or tens of thousands) of standard opening moves that experts agree are a good way to start a game
end game databases: in chess, if the are 6 or fewer pieces left on the board, there are databases that will tell you instantly whether the position is a win, loss, or draw; in practice, this means a chess program doesn’t need to do any searching form positions with 6, or fewer, pieces on the board: it can just look-up the answer in the end game database
the pattern databases we mentioned when discussing the 15-puzzle are similar in spirit to end game databases
- the key idea seems to be to pre-compute lots of simpler/smaller versions of a problem so as to help solve large problems
extension searching: traditional chess programs only have enough time and memory to look ahead a fixed number of moves; but in some situations, the computer might look ahead dozens of more moves because of things like forced moves (e.g. you must always move your king out of check), or because there are very promising moves (e.g. capturing a piece, or putting the kind in check); using extension searches, modern chess programs can occasionally look dozens of moves ahead to find guaranteed checkmates beyond the ability of humans
dynamic positional evaluation: beginning chess players are often taught that pawns are worth 1 point, a bishops/knights are worth 3 points, rooks are worth 5 points, the queen is worth 9 points (and the king is worth infinitely many points); so you can estimate the strength of your position by adding up the points of all your pieces and comparing to the points for your opponents pieces; but, these static point values for pieces are not always correct, e.g. 2 pawns right beside each (“connected pawns”) can be worth much more than 2 points, especially near the end of the game; similarly, a bishop that is blocked from moving anywhere is worth less than 3 points; so good chess programs look for more sophisticated patterns and positions of pieces when evaluating a board, so that the point score of individual pieces might change throughout the game
Games with Randomness¶
importantly, chess is a game with no randomness or hidden information
games that use dice or cards, however, have randomness that is not present in chess
one way to think about randomness in a 2-player game is to imagine that randomness is another player named RAND; RAND gets to make a move at various points in the game, and neither of the other two actual players know exactly what that move will be
this makes a big difference to the kind of algorithms that work well for playing such games!
the addition of randomness no longer makes alpha-beta search the necessarily best algorithm
one generally successful approach to some random games is monte carlo simulation, which has been used to create world-class backgammon and Scrabble programs
a standard twist related to randomness is partial observability
consider the game 7-card stud Poker, where 2 (or more players) have there own hand of 7 cards (taken at random from a deck of 52) that they keep secret from the other players
making probabilistic predictions about what cards your opponent might have is an important poker skill, as the tactic of purposefully trying to confuse your opponent about what cards you have
- e.g. a poker player with a strong hand might act as if they have a weak hand, or vice-versa
Chess, Go, and AlphaZero¶
until about 2017, variations of alpha-beta search were the best chess-playing agents
they essentially combine a lot of human-added chess knowledge with an extremely efficient alpha-beta search
but AlphaZero surprised the chess world by showing that reinforcement learning could be used to learn to play chess at a level comparable to the best alpha-beta style chess agents
furthermore, AlphaZero did its learning in less than 10 hours of self-play (i.e. playing thousands and thousands of games against itself)
- although, to be fair, it did use a huge amount of computational power in those few hours, and did its training in parallel, so much that only a big company like Google could realistically do it
also, AlphaZero does use some searching, but it does not use alpha-beta search
instead, it uses a different technique called Monte-Carlo Tree search (MCTS)
- the basic idea of MCTS is to pick random successor states, and keep going until the game is played out
- this is repeated thousands (or more) times
- then the move that is actually selected is the one that leads to the most wins
- AlphaZero uses a modified version of this: it uses its learned knowledge (in the form of a neural network) to decide what move to make when simulating the games
consider the following news report from April 2019:
- AlphaZero played 1000 chess games against StockFish, generally considered to
be the strongest (or among the strong) traditional alpha-beta style chess
agents
- the games gave each player 3 hours to play their moves, plus 15 seconds extra for each move
- AlphaZero won 155 of the games, lost 6, and drew the remaining 839
- this is generally taken as good evidence that AlphaZero is probably the strongest chess-playing agent that has ever existed, human or otherwise
- using MCTS, AlphaZero searched about 60,000 positions per second
- using alpha-beta search, StockFish searched about 60 million positions per second, i.e. 1000 more positions per second than AlphaZero
- even though StockFish was greatly out-searching AlphaZero, it appears that AlphaZero’s knowledge of chess is superior
- Stockfish has an ELO rating around 3378, and based
on this performance AlphaZero has an ELO rating around 3430
- the higest ever ELO rating rating of a human chess player was for Magnus Carlsen, who had a rating of 2882 in 2014
as impressive as this is, another remarkable fact about AlphaZero is that it is not specific to chess: it has also been used to create the best Go and Shogi agents
- famously, Go is a game that the alpha-beta game tree search approach doesn’t work well with because the branching factor of the game tree is so big
the dramatic success of AlphaZero has sparked the imagination of many people: if a computer can learn more about chess in ten hours than humans have learned in centuries, how long before computers start to similarly out-perform humans in other disciplines?
- but there is still a lot of tough problems to solve — reinforcement learning doesn’t work so well with all games or problems!