


Next: Hash Join
Up: Join Strategies
Previous: Merge-Join
-
Frequently the join attributes form a search key for an index on one of the
relations being joined.
- In such cases we can consider a join strategy that makes use of such
an index.
- Our first join algorithm is more efficient if an index
exists on customer (inner loop relation) for cname.
- Then for a tuple d in deposit, we no longer have to read the
entire customer relation.
- Instead, we use the index to find tuples in customer with the
same value on cname as tuple d of deposit.
- We saw that without an index, we could take as many as 2,010,000 block
accesses.
- Using the index, and making no assumptions about physical storage,
the join can be performed more efficiently.
- We still need 10,000 accesses to read deposit (outer loop
relation).
- However, for each tuple of deposit, we only need an index lookup
on the customer relation.
- As
 and we assumed that 20 pointers fit in one
block, this lookup requires at most 2 index block accesses (depth of
and we assumed that 20 pointers fit in one
block, this lookup requires at most 2 index block accesses (depth of
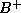 -tree) plus block access for the customer tuple itself.
-tree) plus block access for the customer tuple itself. - This means 3 block accesses instead of 200, for each of the 10,000
deposit tuples.
- This gives 40,000 total, which appears high, but is still better than
2,010,000.
- More efficient strategies required tuples to be stored physically
together.
- If tuples are not stored physically together, this strategy is highly
desirable.
- The savings (1,970,000 accesses) is enough to justify creation of the
index, even if it is used only once.
Osmar Zaiane
Sun Jul 26 17:45:14 PDT 1998